Schon vor vielen Jahren habe ich mich gefragt, ob es technisch überhaupt denkbar ist, der Google-Suchmaschine irgend etwas entgegenzusetzen, um aus deren Beschränkungen zu entkommen.
(Der Bezug auf Google in diesem Artikel ist im Prinzip und uneingeschränkt auch auf andere große kommerzielle Suchmaschinen anwendbar, wie z.B. Microsoft Bing.)
Ok, Google „beschränkt“ zu nennen, mag dreist klingen. Schließlich kennt Google jeden Mückenschiss im Netz. Auch kennt sie (oder er oder es?) die sprichwörtlich minütlich in Asien umfallenden Säcke Reis. Google scannt ja schließlich das ganze Internet. Immer und immer wieder.
– Ja und NEIN! –
Es gibt einen gewaltigen Unterschied zwischen dem, was Google an Quellen im Netz scannt und indiziert und dem, was wir uns aus Google „holen“ können. Man nennt das Ranking: Google bewertet bei einer Suchanfrage, welche Details aus seinem Universum für uns relevant sein sollen. Ich denke, das ist bekannt und ich muss das hier nicht weiter ausführen. Und Duckduckgo als Alternative ist nicht umsonst von Google platziert und massiv gestutzt.
Das Problem ist, dass wir Google sehr schlecht den Kontext mitgeben können, um eine Suchanfrage optimal zu platzieren. Statt dessen scannt Google (und andere Firmen, dessen Namen wir nie gehört haben und haben werden) unser Verhalten am Rechner und berechnet den Kontext selbst. Die Berechnung ist dahingehend optimiert, unser Kaufverhalten auf deren Werbekunden zu lenken. Es versagt, wenn wir etwas suchen, was wir gar nicht kaufen wollen: gesellschaftliche oder wissenschaftliche Informationen. Google-Scholar ist hier eine segensreiche Ausnahme. Danke Alphabet-Universum! Immer lebe Deine Energie, die Server am Laufen zuhalten. Ich preise Dein Wissen und Deine Macht!
Genug der Konzernschelte in einer Zeit in der das Verb twittern vermutlich bald x’n heißen soll. Ich glaube nicht, dass das gesellschaftsfähig ist. X’n ist doch eher ein gut funktionierendes Synonym um mit dem Freund oder der Freundin Schluss zu machen. Oder das Studium zu schmeißen…
Yacy
Bevor ich erst lange den Spannungsbogen biege: Es gibt nach dem Prinzip des Fedivers auch seit vielen Jahren schon eine Suchmaschine, die im Verbund mit vielen Nutzern Google Konkurrenz machen könnte und kann: Yacy. Ich mag jedoch an dieser Stelle nicht bewerten, warum derzeit weder Mastodon noch Yacy on vogue sind. Vielleicht wird sich das in Zukunft noch ändern. Mastodon ist zumindest seit längerer Zeit im Gespräch und in zunehmender Nutzung, seit der Elon sich das Vögelchen gekrallt hat.
Yacy ist mächtig und auch ideal, um eine Behörden- oder Firmenwebsite für die eigenen Angestellten durchsuchbar zu machen. Das Prinzip eignet sich sogar für extrem große Organisationen. Die Software ist frei nutzbar. Die seit viel Jahren aktiven Macher der Suche-Engine verdienen ihr Geld mit Consulting und Implementing in diversen Firmen. Warum sollte man so eine Möglichkeit links liegen lassen?
Die jetzt im Aufbau befindliche Zoologisch-Botanische Suchmaschine von Karlincam.cz beruht auf diesem Prinzip und dieser Software.
Nicht ganz. Yacy bringt zwar eine große Vielfalt an Kontrollmöglichkeiten mit, das Crawlen des Netzwerkinhalts zu dirigieren. Ebenso die Inhalte mit dem Begriff Relevanz in Verbindung zu bringen. Etwas mehr Know-How ist dann doch noch erforderlich, um eine fachspezifische Suchmaschine aufzusetzen:
- Detaillierte Analyse der zu durchsuchenden Websites, um den entsprechenden Crawl-Auftrag zu formulieren.
- Sonderbehandlung mit zusätzlicher Software, um relevanten Inhalt von Unrelevantem zu trennen. Oder einfach nur, um (wie bei Wikipedia), sicherzustellen, jede Webseite zu durchsuchen, aber nur den inhaltlich relevanten Inhalt zu indizieren.
- Jedoch zu aller-erst: Die Aufnahme von fachspezifischen Inhalten per Hand zu recherchieren und von für die Suchmaschine nutzlosem Material auf den entsprechenden Webseiten zu trennen.
Wikipedia indizieren?
Ja klar! Natürlich kann man das! Es hat zwar eines zusätzlichen Geschützes bedarf, Privoxy als man-in-the-middle, um effizient, wie Datensparsam vorzugehen. Aber es funktioniert. In der deutschen, englischen und natürlich auch tschechischen Version. Der zweite große „Brocken“ ist Zobodat. Dazu ein eigener Artikel:
Derzeit erfolgt die schrittweise Erfassung von Veröffentlichungen deutscher ornithologischer Vereinigungen. Entomologische Seiten gibt es ebenfalls, die für die Indizierung noch erschlossen werden wollen. Und ich bin gespannt, welche Fachgebiete noch so möglich sind. Die Orientierung ist auf den deutschen und tschechischen Sprachraum ausgerichtet. Insofern Publikationen in englisch vorhanden sind, die sich auf das Territorium von Deutschland, Tschechische Republik, Slowakei, Österreich und der Schweiz beziehen, werden diese mit aufgenommen. Allerdings ist das nicht einfach zu selektieren, da die entsprechenden Open-Access-Medien natürlich andere Inhaltsbegrenzungen umfassen, als dieses spezielle Territorium. Wir werden sehen.
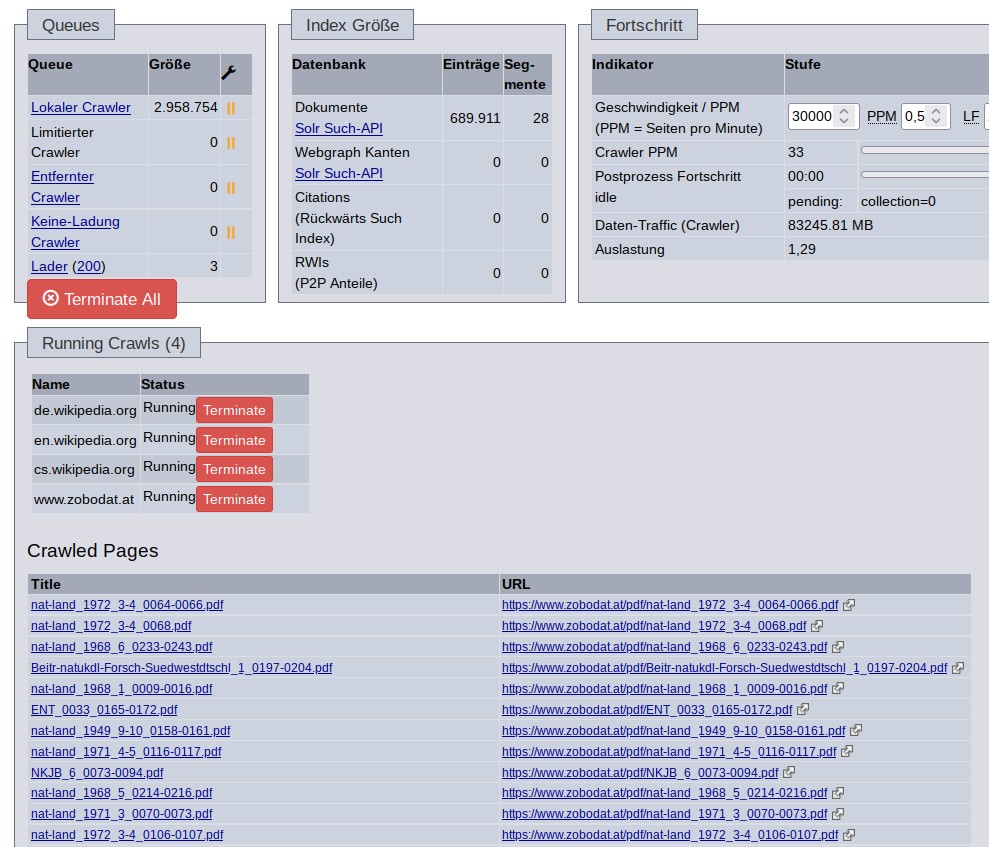
Aktuell liegen wir bei über 350 Tausend indizierter Webseiten oder PDFs. Wer die Suchmaschine schon mal testen möchte (in diesen Monaten hin und wieder kurzzeitig offline, wenn Optimierungen und Erweiterungen an der Software erfolgen):
Durch die indizierte ZOBODAT-Datenbank sind Suchergebnisse sehr ZOBODAT- und damit mit historischen Artikeln „belastet“. In unserer finalen Such-Page werden wir solche Besonderheiten berücksichtigen. Wer die zwischenzeitliche Suchschnittstelle hier nutzt, kann bei Bedarf den Index der ZOBODAT-Datenbank ausschließen, indem er ins Suchfeld zusätzlich
-zobodateingibt. Also mit dem Minus-Zeichen davor.
Frank 6. September 2023 — Autor der Seiten
Hallo nochmal,
Das Projekt ist derzeit in einem frühen Stadium. Die technischen Voraussetzungen sind seit gestern jedoch auf einem recht hohen Niveau gelöst:
Die erste qualitative Hürde, das Crawling und Indexing sehr fein auf die Quelle abzustimmen, ist durch die Erweiterung mit dem Privoxy-System sehr erfolgreich umgesetzt. Aber nicht nur das. Mit der Privoxy-Integration ist es gelungen, auch bei extrem großen Websites, wie der Wikipedia, Ressourcen zu sparen. Beim Crawling wurde es möglich, ausschließlich Artikelseiten sowie die Links unter „Alle Seiten“ zu verfolgen, während alle anderen Links nicht mal mehr in die Crawling-Queue übernommen werden (um sie dann später auf Grund ausschließender Regeln zu verwerfen).
Bisher gab es aber noch das Problem, dass im Falle einer zu langsamen Antwort eines Servers während des Crawlings die Antwort, und damit deren Inhalt verloren ging. Ich habe nun einen Observer programmiert, der solche Ereignisse abfängt und die Zieladressen für eine spätere Indizierung archiviert.
Weiterhin hat das Privoxy-System die Möglichkeit geboten, die Indizierung unwesentlicher Teile einer Seite zu verhindern. Für das Crawling von kleinen Web-Präsenzen ist das eher unerheblich. Auch für Zobodat.at ist das nicht relevant, weil nur die archivierten PDF indiziert werden. Bei den Wikipedia-Artikeln lohnt sich eine entsprechende Filterung mit Privoxy aber erheblich. Beim Indexer kommen nun nur noch die eigentlichen Artikelinhalte an und nicht mehr das organisatorische Drum-Herum der Wikipedia. Entsprechend weniger unwichtiger aber speicherplatzverbrauchende Indexeinträge müssen auf der Festplatte abgelegt werden.
Der Speicherverbrauch während des Crawling sowie der Zuwachs an Index-Daten bestätigt die erfolgreiche Umsetzung der Filtermechanismen.
Frank
Frank 19. September 2023 — Autor der Seiten
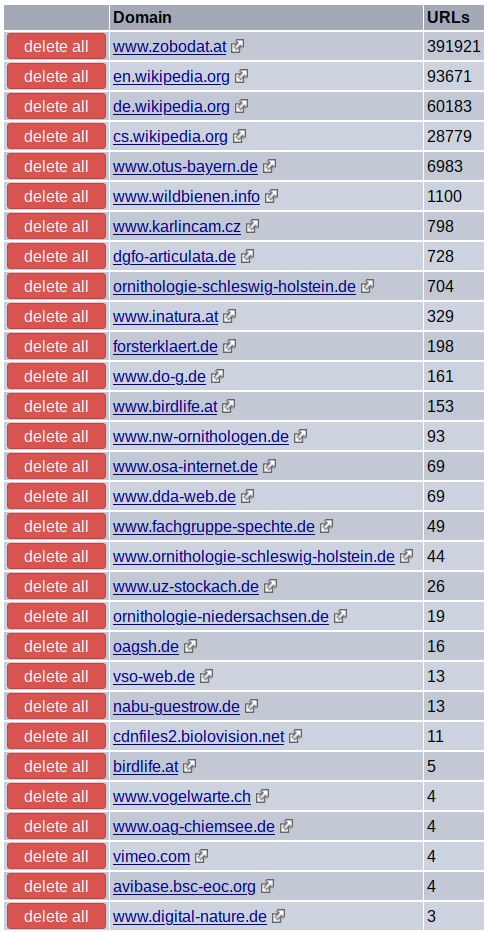
Inzwischen ist auch das Crawling der tschechischen und deutschen Wikipedia abgeschlossen. Einige Terra-Bytes wurden über den Server heruntergeladen. Aber natürlich wurden nur sinnvolle Lebewesen indiziert: Keine Fußballer, keine Politiker, keine Filmstars. Nur die einfachsten Lebewesen. Damit dürften zumindest die Wikipedia-Seiten der wesentlichsten Tiere und Pflanzen in unserem Raum verlinkt sein.
Die englische Wikipedia ist erheblich umfangreicher. Wir befinden uns derzeit beim Wortanfang Bi… Aber das ist nicht wirklich wichtig.
Weiterhin hat sich die Österreichiche Datenbank Zobodat als die entscheidende Archäologische Gesellschaft entpuppt, die eine Unmenge an Literatur von heute bis in historische Zeiten zurück im dem deutschen Sprachraum archiviert hat. – Auch diese wird hier noch indiziert und umfasst derzeit erheblich mehr Dokumente als die Wikipedia in deutsch, tschechisch und englisch zusammen als Arten von Lebewesen umfasst.
Frank 20. September 2023 — Autor der Seiten
Warum uns gerade die Grasfrösche des Nachts das Haus einrennen ist vollkommen unklar! Und so richtig lustig ist das auch nicht: Sobald man sich sehen lässt, verschwinden die kleinen Einjährigen unter den Möbeln. Und kommen nicht mehr hervor. Wir können sie so nicht ohne Weiteres wieder nach draußen bringen.
Zurück zum Crawling.
Das große Ziel hier ist vor allem, die Veröffentlichungen der lokalen Vereine und Experten im Netz besser sichtbar zu machen. Der administrative Aufwand ist erheblich, wie ich nach den ersten Wochen feststellen kann. Aber abgesehen vom Aufwand, eine selektive Suchmaschine zu betreiben: Wo liegen die Probleme des öffentlichen Zugriffs auf forschungs- und damit wissensrelevanter Daten der Vereine? Alles gruppiert sich in 2 Klassen:
1) Vereine mit wenig Publikationsscheu stellen alle ihre Erkenntnisse ins Internet. Der Web-Admin jedoch (sofern es ihn noch gibt und er nicht nur beim Aufsetzen der Website im Verein aktiv war) lässt diese Publikationen, im Wesentlichen wohl völlig unbewusst, auf der Vereinswebseite verstecken. – Das ist keine Absicht, aber leider auf Grund technischer Unerfahrenheit erschreckend häufig der Fall. Oft sind die Seiten zwar mittels händischer Suche zu finden, jedoch werden Suchmaschinen blockiert, diese Inhalte zu indizieren.
2) Vereine mit einer langen Historie gedruckter Publikationen glauben, dass sie der Nabel der Welt sind und ihre Publikationen gekauft werden müssen, damit sie ihrer Relevanz gerecht werden. Abgesehen davon, dass die meisten Publikationen nach der Verteilung an die Vereinsmitglieder längs vergriffen sind. Hier liegt das größere Problem gegenüber 1): Nur als Beispiel: Der Verein Sächsischer Ornithologen hat seit Jahren mit begrenztem Erfolg eine örtliche Einrichtung als Bibliothek ihrer Jahrzehnte zurückliegenden Publikationen gesucht, anstatt die Werke einfach in guter Qualität zu scannen und digital öffentlich zu stellen (z.B. bei Zobodat).
Ich bin zwar aktuell vor allem beim Publikationssammeln der ornithologischen Veröffentlichungen und deshalb von einem gewissen Bias betroffen. Ich werde aber das Gefühl nicht los, dass vor allem die Ornithologen die am weitesten konservativ eingestellten Naturliebhaber sind. (Natur-„forscher“ würden mit maximaler Sichtbarkeit publizieren.) Also lieber ihre Schriften im eigenen „Tank“ konservieren, als sie zu digitalisieren und damit weltweit durchsuchbar und nutzbar zu machen. Wenn ich mich im Detail täuschen sollte: Um so besser.
Ich führe aktuell eine Dokumentation zur Indizierung. Wer also Details wissen will, findet sie dort tatsächlich hoch detailiert:
* https://www.karlincam.cz/search-karlincam-cz
* https://www.karlincam.cz/search-karlincam-cz/search-karlincam-cz-ornithologie